Reasoning Gym Paper
Reasoning Gym aims to facilitating the training and evaluation of reasoning models by providing procedural dataset generators with the ability to generate virtually infinite diverse samples with finegrained difficulty configurations.
Today we released our paper on arXiv. I also wrote a thread with some of the key details.
Interesting Tidbits
We find that Reasoning Gym is a highly effective evaluation of frontier models’ problem solving capabilities. Here are results of several models on RG hard configs:
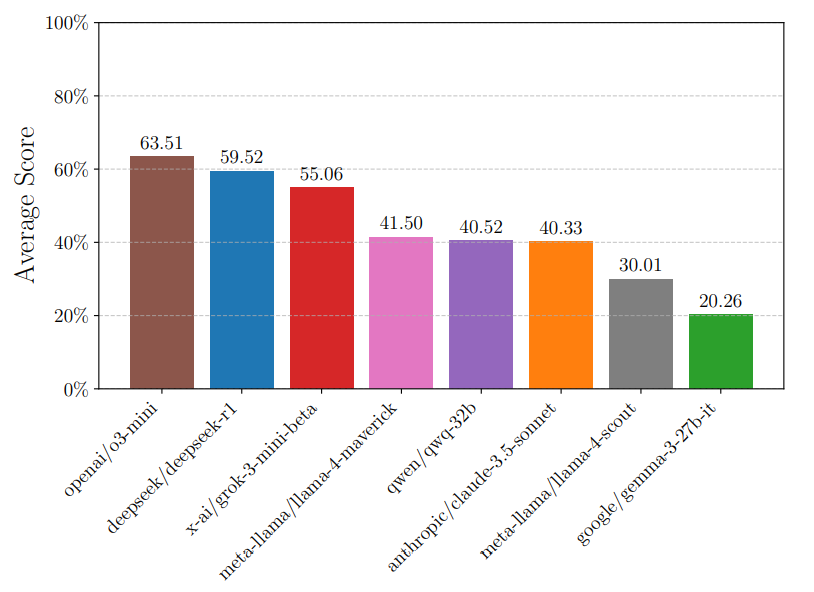
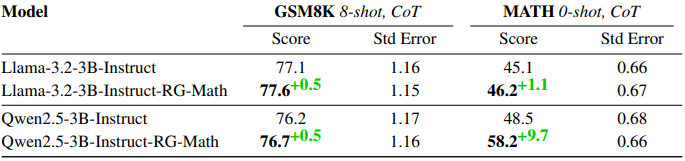
Additionally, we run some small RL experiments and find that RLVR on RG mathematics data can improve models on common LLM benchmarks at the 3B scale.
RG has already been adopted for training and evaluation by NVIDIA researchers in their ProRL paper.
It’s also possible to use RG data in William Brown’s popular verifiers RL library, since he built a direct integration. Thanks to Will!
The Future
We want to build an even bigger library of reasoning environments. If you have ideas, please feel free to let us know, or even contribute datasets generators directly via pull requests to our repository.
Running more evaluations is also of interest. If anyone has OpenRouter or other API provider credits, we’d love to find out how more frontier models fare on RG tasks.